RGB↔X: Image Decomposition and Synthesis Using Material- and Lighting-aware Diffusion Models
Zheng Zeng, Valentin Deschaintre, Iliyan Georgiev, Yannick Hold-Geoffroy, Yiwei Hu, Fujun Luan, Ling-Qi Yan, Miloš Hašan
ACM SIGGRAPH 2024 (Conference Track)
paper, code, slides, supplementary, doi
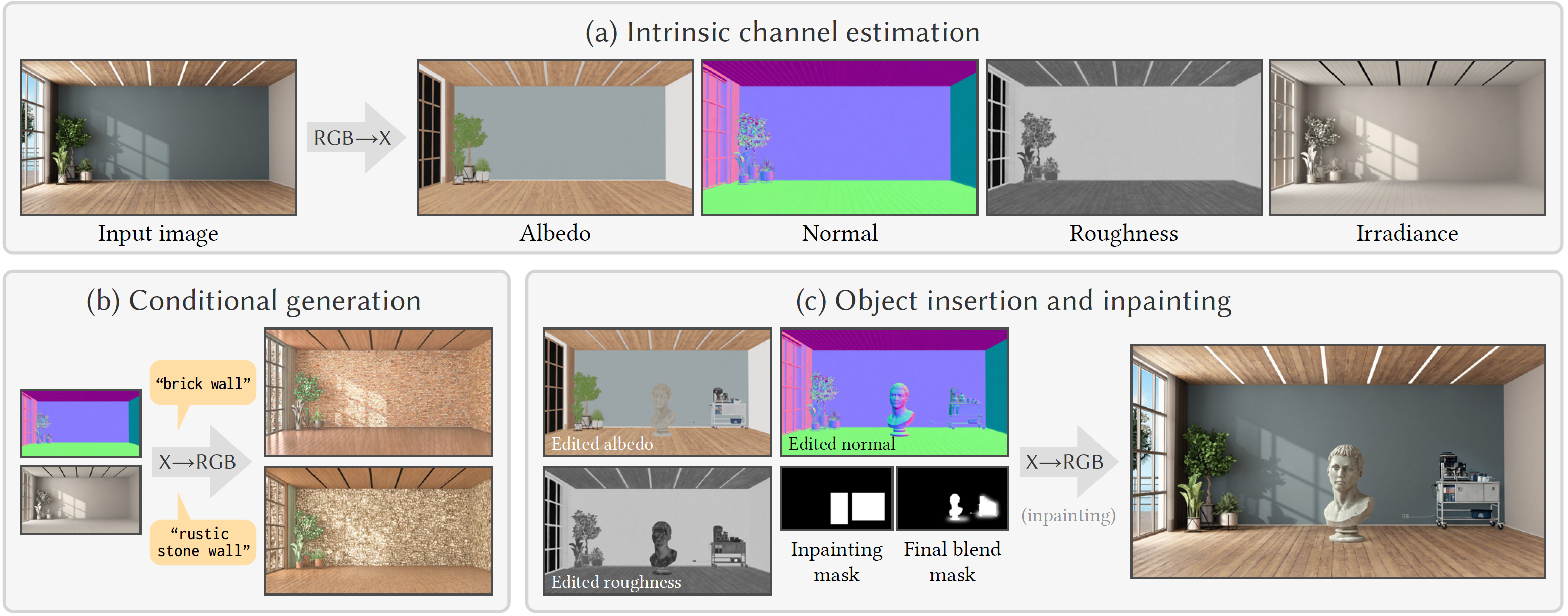
What is RGB↔X?
RGB↔X is a unified diffusion-based framework that enables realistic image analysis (intrinsic channel estimation, denoted as RGB→X) and synthesis (realistic rendering given the intrinsic channels, denoted as X→RGB).
RGB↔X explores the connections between diffusion models, realistic rendering, and intrinsic decomposition. We believe it can bring benefits to a wide range of downstream tasks, including material editing, relighting, and realistic rendering from simple/under-specified scene definitions.
Why using diffusion models on intrinsic decomposition?
The intrinsic decomposition problem is inherently diffcult due to its under-constrained nature, including the ambiguity between illumination and materials.
Consider this simple example:

There are strong reflections and shadows on the wooden floor. Previous non-diffusion-model-based methods fail to recover the correct albedo channel.
Recent amazing work by Kocsis et al. has demonstrated improved estimation of intrinsic channels based on a diffusion model. They observe that further progress in this domain is likely to use generative modeling. We follow this direction further.
Why using diffusion models on realistic rendering?
Typical generative models are simple to use but hard to precisely control. Quoting Andrew Price in his weekly 3D news about Sora: “Getting any result is easy. But getting a specific result is often impossible.”
On the other hand, traditional rendering is precise but requires full scene specification, which is sometimes limiting.
We explore a middle ground where we specify only certain appearance properties that should be followed, and give freedom to the model to hallucinate a plausible version of the rest.
Having the (traditional) rendering knowledge in the diffusion framework could be the key to guarantee controllability and consistency. We believe this direction could enable applications like disentangled photo editing, fast previews of renderings for 3D software, CG-to-real approaches, and more.
💡 One interesting idea is to first obtain a normal map and irradiance map from the pure geometry and lightings, then use the X→RGB model to produce "rendering" images; following this, employ a differentiable renderer to optimize the material parameters based on these images. With this way, you'll have not only a preview of the rendering but also a full scene with corresponding materials that you can do further authoring. This entire process is possible to be simplified by using the Score Distillation Sampling (SDS) technique.
How does it work?
RGB↔X is enabled by two our fine-tuned diffusion models:
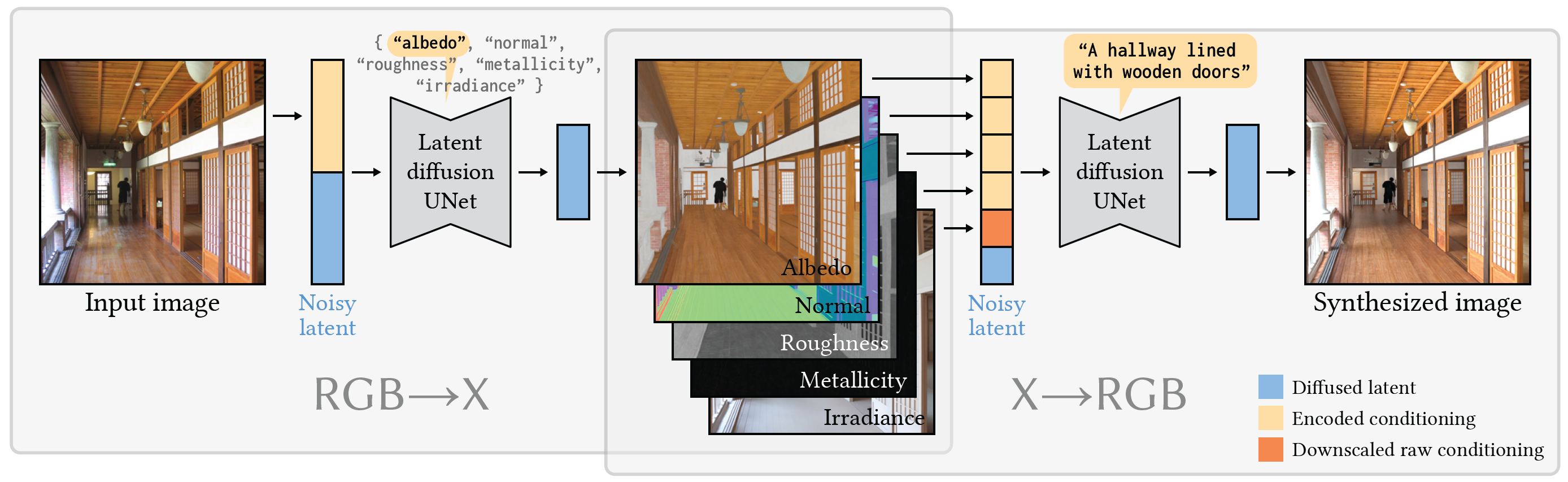
The RGB→X model performs intrinsic decomposition: estimating per-pixel intrinsic channels (X) from an image (RGB).
- Repurpose the input text prompt as a “switch” to control the output and produce a single intrinsic channel at a time.
- Enable usage of a mix of heterogeneous datasets, which differ in the available channels.
- For example, a dataset with only albedo channel available can still be employed to train our model.
The X→RGB model synthesizes an image (RGB) from full or partial intrinsic channels (X).
- Channel drop-out training strategy: randomly drop conditioned channels during training.
- Again, enable usage of a mix of heterogeneous datasets, which differ in the available channels.
- Enable image generation with any subset of conditions.
How well it works?
RGB→X results

X→RGB results


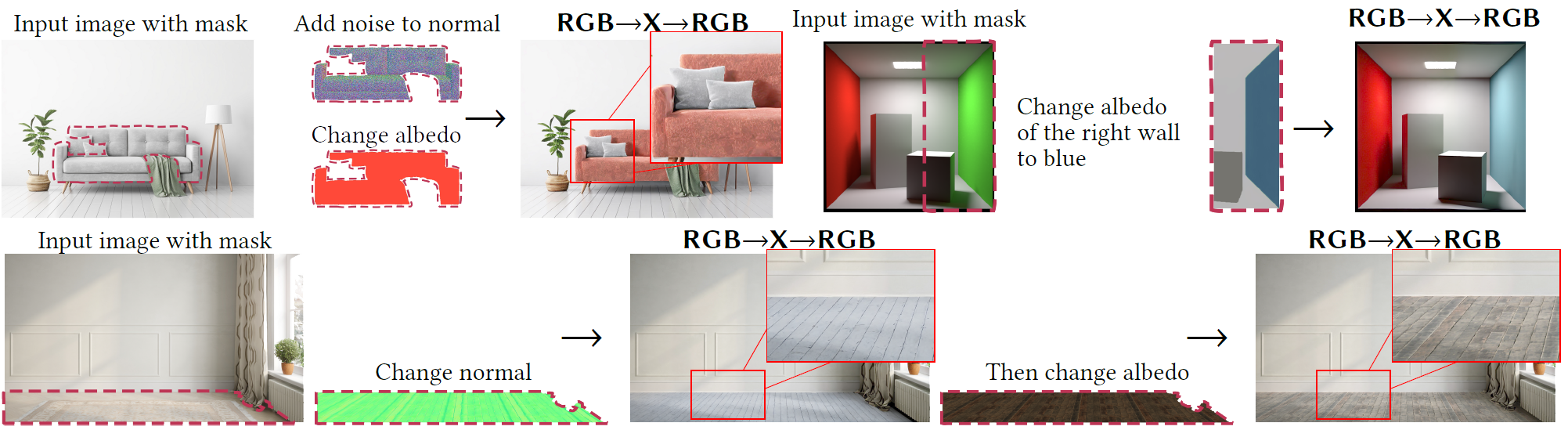
RGB→X→RGB results
Other interesting results: famous people and places
(Note that these images are clearly out of our training distribution.)
Other interesting results: anime pictures
(Note that these images are clearly out of our training distribution. Thanks toyxyz for creating this!)
Acknowledgments
We thank the anonymous reviewers for their constructive suggestions. We also thank toyxyz for creating the ComfyUI Wrapper and the anime results! This work was done while Zheng was an intern at Adobe Research.
Cite
@inproceedings{zeng2024rgb,
author = {Zeng, Zheng and Deschaintre, Valentin and Georgiev, Iliyan and Hold-Geoffroy, Yannick and Hu, Yiwei and Luan, Fujun and Yan, Ling-Qi and Ha\v{s}an, Milo\v{s}},
title = {RGB↔X: Image decomposition and synthesis using material- and lighting-aware diffusion models},
year = {2024},
isbn = {9798400705250},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3641519.3657445},
doi = {10.1145/3641519.3657445},
booktitle = {ACM SIGGRAPH 2024 Conference Papers},
articleno = {75},
numpages = {11},
keywords = {Diffusion models, intrinsic decomposition, realistic rendering},
location = {Denver, CO, USA},
series = {SIGGRAPH '24}
}